今日值得关注的大模型前沿论文
浙大、北航团队提出可控视频生成方法 AnimateAnything
腾讯、复旦团队提出 FitDiT:让「虚拟试穿」更真实
SmoothCache:扩散 Transformer 的通用推理加速技术
南京大学团队提出区域感知文生图方法 RAG
vivo 提出 BlueLM-V-3B:在移动平台上高效部署 MLLM
字节团队提出大模型训练优化框架 MARS
大模型后训练新范式:中科院、阿里和小红书团队提出「验证器工程」
想要第一时间获取每日最新大模型热门论文?
点击阅读原文,查看“2024必读大模型论文”
ps:我们日常会分享日报、周报,后续每月也会出一期月报,敬请期待~
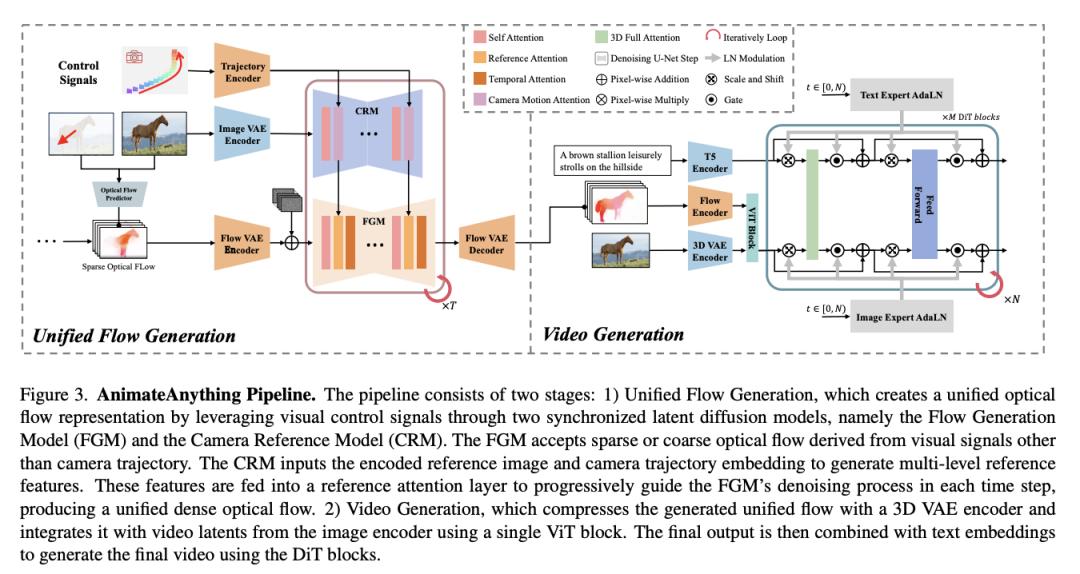
浙大、北航团队提出可控视频生成方法 AnimateAnything
来自浙江大学和北京航空航天大学的研究团队及其合作者提出了一种统一的可控视频生成方法 AnimateAnything,它有助于在各种条件下进行精确一致的视频操作,包括相机轨迹、文本提示和用户动作注释。
具体来说,他们设计了一个多尺度控制特征融合网络,为不同条件构建通用的运动表示。它明确地将所有控制信息转换为逐帧光流。然后,他们将光流作为运动先验来指导最终视频的生成。此外,为了减少大范围运动引起的闪烁问题,他们提出了基于频率的稳定模块。它可以通过确保视频的频域一致性来增强时间一致性。
论文链接:
https://arxiv.org/abs/2411.10836
项目地址:
https://yu-shaonian.github.io/Animate_Anything/
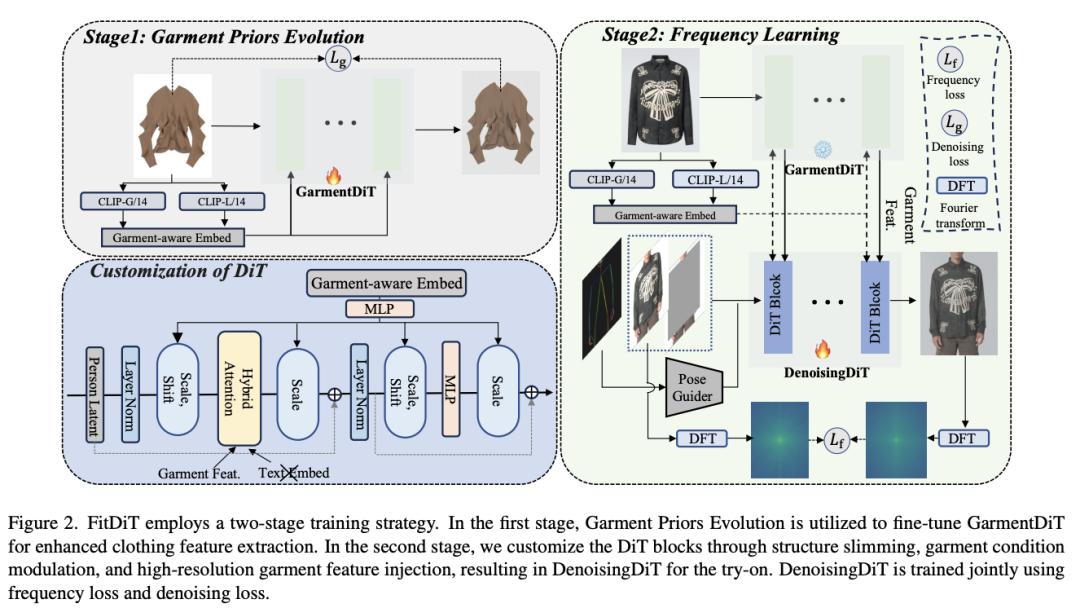
腾讯、复旦团队提出 FitDiT:让「虚拟试穿」更真实
尽管基于图像的虚拟试穿取得了长足进步,但新兴方法在不同场景下生成高保真和鲁棒的试穿图像方面仍面临挑战。这些方法往往难以解决纹理感知保持和尺寸感知拟合等问题,从而阻碍了其整体效果。
为了解决这些局限性,来自腾讯和复旦大学的团队提出了一种新颖的服装感知增强技术,称为 FitDiT,该技术专为高保真虚拟试穿而设计,使用扩散 Transformer(DiT)将更多参数和注意力分配给高分辨率特征。首先,为了进一步改进纹理感知保持,他们引入了服装纹理提取器,该提取器结合了服装先验进化来微调服装特征,从而有助于更好地捕捉条纹、图案和文字等丰富细节。此外,他们还引入了频域学习,通过自定义频率距离损失来增强高频服装细节。
为了解决尺寸感知试衣问题,他们采用了一种扩张-松弛(dilated-relaxed)掩码策略,以适应服装的正确长度,防止在跨类别试穿时产生充满整个掩码区域的服装。有了上述设计,FitDiT 在定性和定量评估中都超越了所有基准。它在制作具有逼真和复杂细节的合身服装方面表现出色,同时在 DiT 结构瘦身后,单张 1024x768 图像的推理时间仅为 4.57 秒,优于现有方法。
论文链接:
https://arxiv.org/abs/2411.10499
项目地址:
https://byjiang.com/FitDiT/
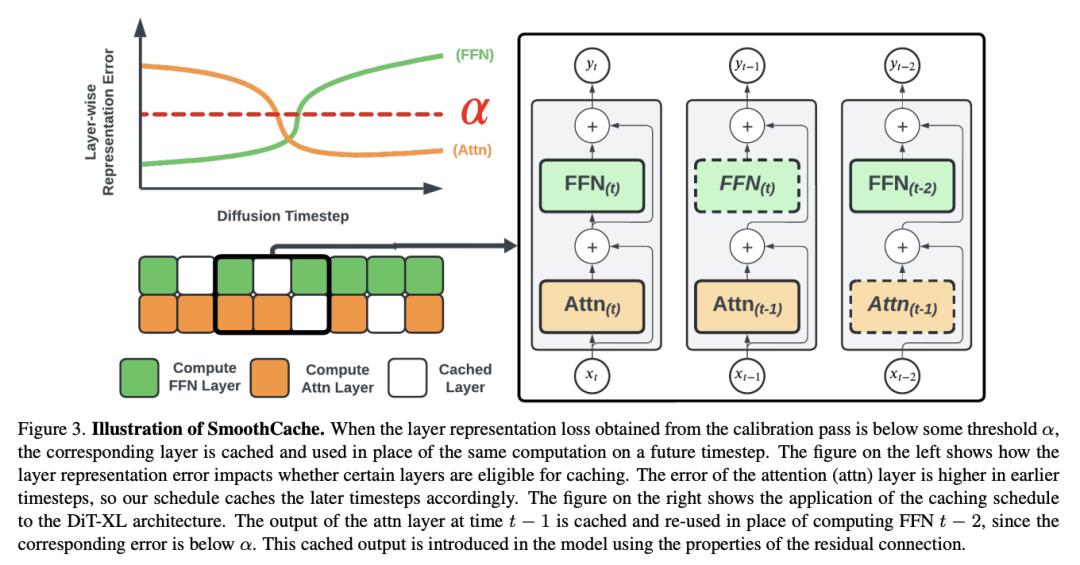
SmoothCache:扩散 Transformer 的通用推理加速技术
扩散 Transformer(DiT)已成为图像、视频和语音合成等各种任务的强大生成模型。然而,由于需要重复评估资源密集型注意力和前馈模块,其推理过程的计算成本仍然很高。
为了解决这个问题,来自 Roblox 和女王大学的研究团队提出了 SmoothCache,这是一种与模型无关的 DiT 架构推理加速技术。SmoothCache 利用了在相邻扩散时间步之间观察到的层输出之间的高度相似性。通过分析来自小型校准集的分层表示错误,SmoothCache 可以在推理过程中自适应地缓存和重用关键特征。
他们的实验证明,SmoothCache 在保持甚至提高不同模态的生成质量的同时,实现了 8% 到 71% 的加速。他们展示了它在图像生成模型 DiT-XL、视频生成模型 Open-Sora 和音频生成模型 Stable Audio Open 上的有效性,突出了它在实现实时应用和扩大 DiT 模型的可用性方面的潜力。
论文链接:
https://arxiv.org/abs/2411.10510
GitHub 地址:
https://github.com/Roblox/SmoothCache
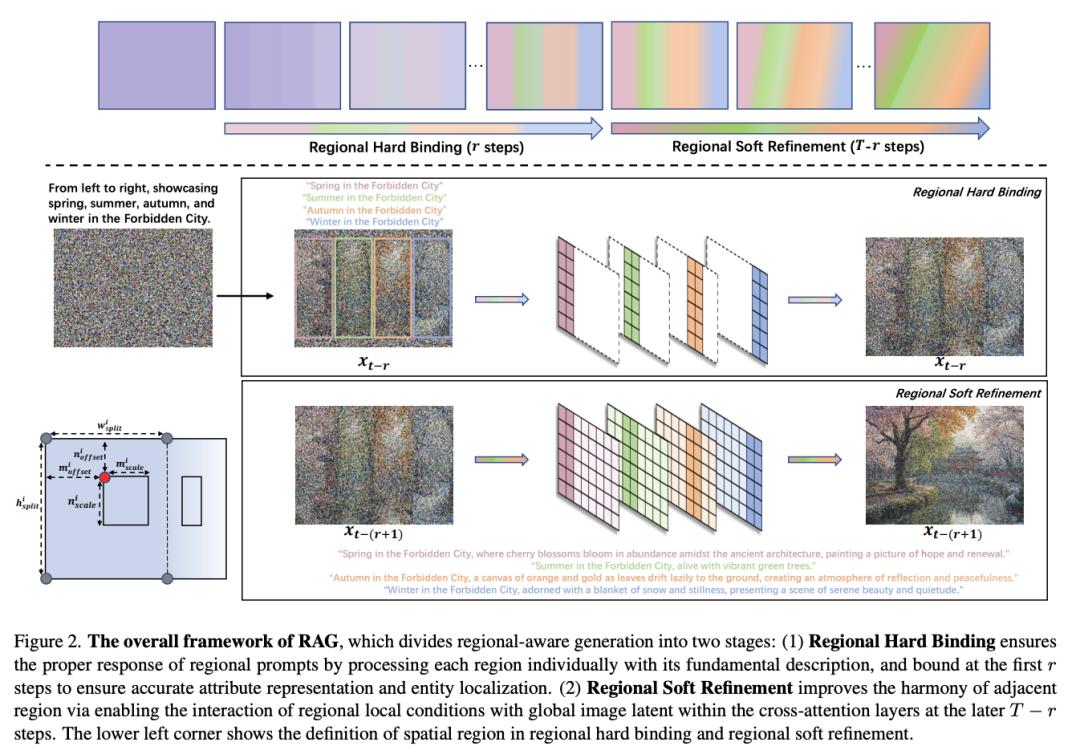
南京大学团队提出区域感知文生图方法 RAG
区域提示或合成生成能够实现细粒度的空间控制,因其在实际应用中的实用性而日益受到关注。然而,以往的方法要么是引入额外的可训练模块,因此只适用于特定的模型,要么是使用注意力掩码在交叉注意力层内的分数图上进行操作,导致当区域数量增加时控制强度有限。
为了解决这些局限性,来自南京大学的研究团队及其合作者提出了 RAG,一种以区域描述为条件的区域感知文生图方法,可实现精确的布局组合。RAG 将多区域生成解耦为两个子任务,一个是单个区域的构建(区域硬绑定),以确保正确执行区域提示;另一个是区域整体细节细化(区域软细化),以消除视觉边界并增强相邻互动。
此外,RAG 还创新性地实现了重新绘制,用户可以修改上一代中不满意的特定区域,同时保持所有其他区域不变,而无需依赖额外的内绘模型。他们的方法无需微调,并适用于其他框架,是对提示跟随特性的增强。定量和定性实验证明,RAG 在属性绑定和对象关系方面的性能优于之前的免微调方法。
论文链接:
https://arxiv.org/abs/2411.06558
GitHub 地址:
https://github.com/NJU-PCALab/RAG-Diffusion
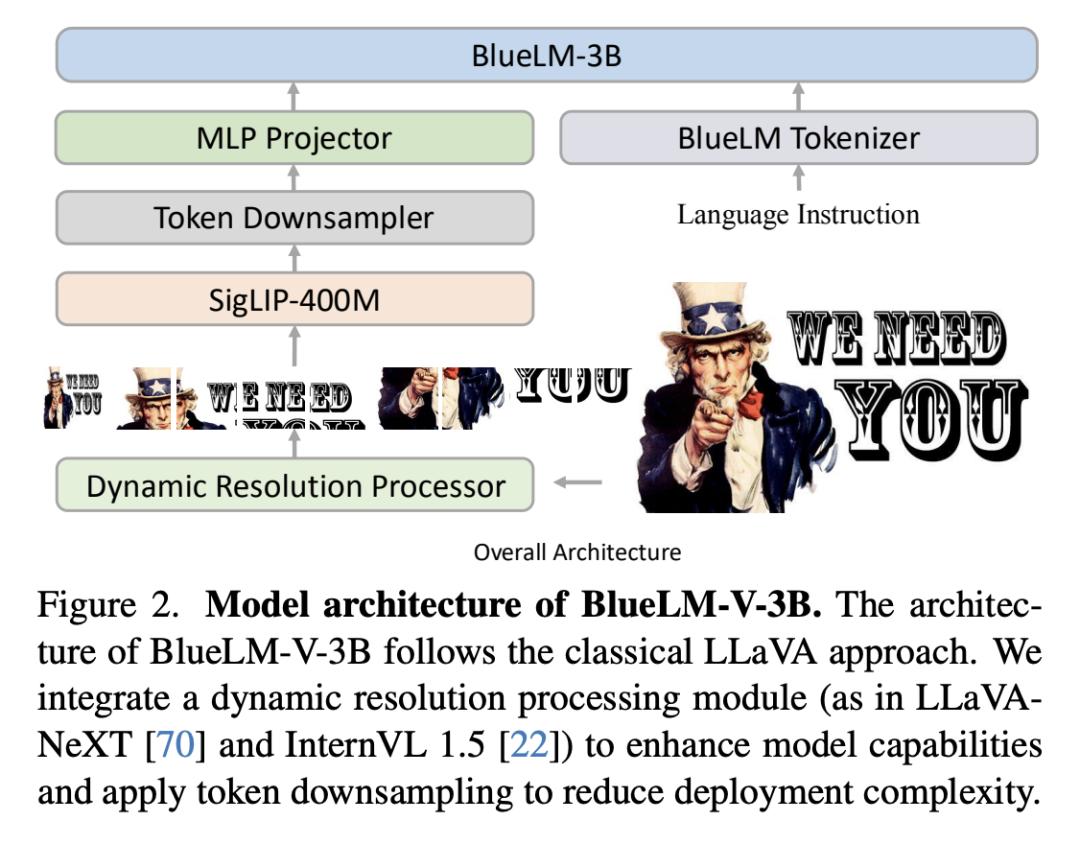
vivo 提出 BlueLM-V-3B:在移动平台上高效部署 MLLM
多模态大语言模型(MLLM)的出现和日益普及,在改善交流、促进学习和解决问题等日常生活的各个方面都具有巨大的潜力。手机作为人们日常生活中必不可少的伴侣,是最有效、最方便的 MLLM 部署平台,可将其无缝集成到日常任务中。然而,由于内存大小和计算能力的限制,在手机上部署 MLLM 面临着挑战,如果不进行大量优化,就很难实现流畅的实时处理。
在这项工作中,来自 vivo AI Lab 和香港中文大学 MMLab 的研究团队提出了一种算法和系统协同设计方法——BlueLM-V-3B,专门用于在移动平台上高效部署 MLLM。具体来说,他们重新设计了主流 MLLM 采用的动态解析方案,并针对硬件感知部署实施了系统优化,以优化手机上的模型推理。
BlueLM-V-3B 具有以下亮点:(1)体积小:BlueLM-V-3B 的语言模型有 2.7B 个参数,视觉编码器有 400M 个参数。(2)速度快:BlueLM-V-3B 在联发科 Dimensity 9300 处理器上实现了 24.4 token/s 的生成速度,并采用 4 位 LLM 权重量化。(3)性能强:在参数小于 4B 的模型中,BlueLM-V-3B 在 OpenCompass 基准测试中获得了 66.1 的最高平均分,并超越了一系列参数更大的模型(如 MiniCPM-V-2.6、InternVL2-8B)。
论文链接:
https://arxiv.org/abs/2411.10640
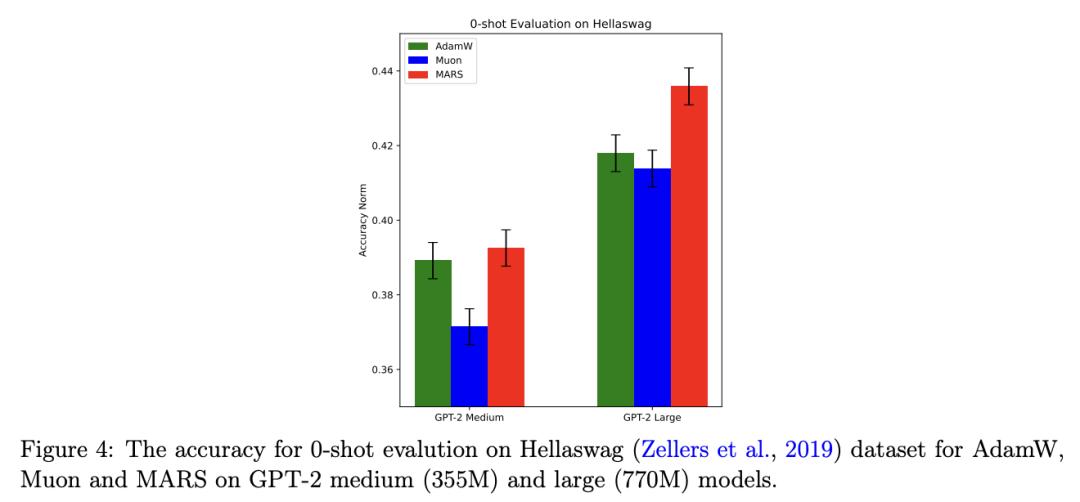
字节团队提出大模型训练优化框架 MARS
训练深度神经网络——以及最近的大模型——需要高效且可扩展的优化器。自适应梯度算法(如 Adam、AdamW 及其变体)一直是这项任务的核心。尽管在过去的十年中开发出了许多旨在加速凸和非凸环境下随机优化的方差缩减算法,但在训练深度神经网络或大语言模型(LLM)方面,方差缩减算法并没有取得广泛的成功。因此,在现代人工智能中,它仍然是一种不太受欢迎的方法。
在这项工作中,为了在大模型的高效训练中释放减小方差的力量,来自字节跳动的研究团队及其合作者提出了一个统一的优化框架 MARS(Make vAriance Reduction Shine),它通过规模随机递归动量技术调和了预条件梯度方法和方差缩减方法。在他们的框架内,他们介绍了 MARS 的三个实例,它们分别利用了基于 AdamW、Lion 和 Shampoo 的预条件梯度更新。他们还将他们的算法与现有的优化器联系起来。训练 GPT-2 模型的实验结果表明,MARS 的性能始终大大优于 AdamW。
论文链接:
https://arxiv.org/abs/2411.10438
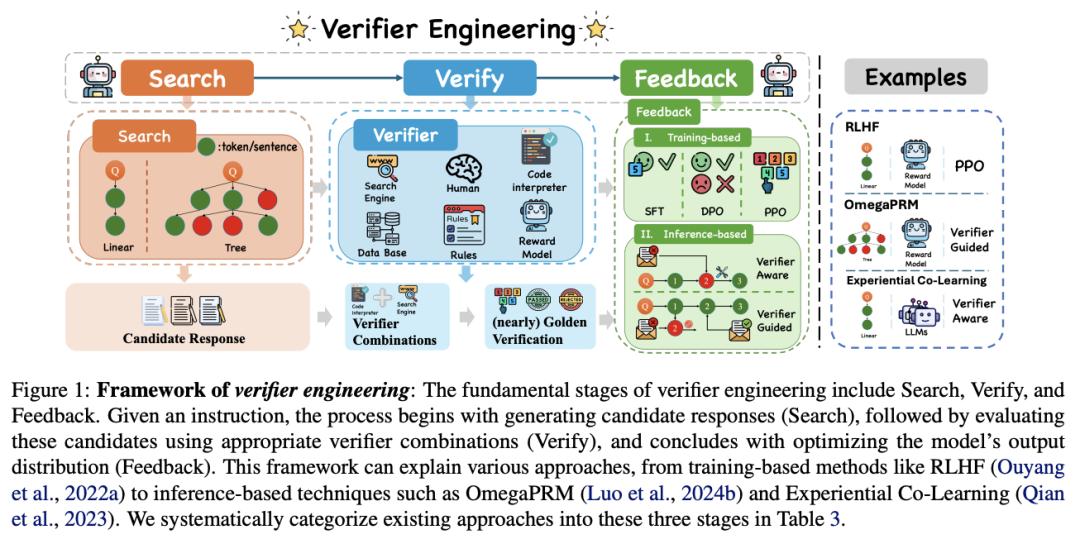
大模型后训练新范式:中科院、阿里和小红书团队提出「验证器工程」
机器学习的发展越来越优先考虑开发功能强大的模型和更具可扩展性的监督信号。然而,基础模型的出现给提供进一步提高其能力所需的有效监督信号带来了巨大挑战。因此,迫切需要探索新的监督信号和技术方法。
在这项工作中,来自中国科学院、阿里巴巴和小红书的研究团队提出了验证器工程,这是一种专为基础模型时代设计的新型后训练范式。验证器工程的核心是利用一套自动验证器来执行验证任务,并向基础模型提供有意义的反馈。他们将验证器工程过程系统地分为三个基本阶段:搜索、验证和反馈,并对每个阶段的 SOTA 研究进展进行了全面回顾。
论文链接:
https://arxiv.org/abs/2411.11504